

The type of questions most commonly asked of an SEO specialist varies over time, and it seems to go in cycles. Recently, I’ve been getting more and more questions about penalties of various kinds, and it seems that there is some confusion around the terminology. That’s why we’re going to unravel the jungle of filters and penalties that make up Google’s search results. “Penalties” are quite complicated matters when it comes to SEO, and it can be hard to know exactly what has happened and why.
Two versions of “the same” thing
To begin with, there are two different mechanisms to consider, both of which can have the same effect. What is traditionally called a “penalty” is what Google now refers to as “manual actions.” It’s simply a human who has looked at either the site as a whole or a specific aspect of the site and made a decision about how Google wants to display that site in its search results. The other mechanism is “filters.” These are various algorithms that change what Google displays in its search results.
To understand what you may have been affected by and to figure out how to fix what’s gone wrong, it’s important to understand how Google builds its search results and how and when these two types of changes affect that process. Simplified, you can say that when someone makes a search on Google, a process is triggered where a large number of algorithmic calculations are made in order to present the best list of results possible for the person searching. The foundation here is PageRank, which uses links to calculate which page is the best for the specific search. On top of that, many other aspects are added to refine the “base result.” Linguistic relevance is calculated, site speed, text length, number of pages, and so on. Google asks itself if it’s a search with a local connection that would require a map. Or if there might be news value and it would be good to show a “News box.” Images? Knowledge Graph?
The list continues, and each calculation can change the result. Only now, when there is a final search result, do the filters apply. It’s important to remember that it’s the search result itself that is filtered, not the site or page. Manual actions, on the other hand, can be applied at any point in this process, depending on the type of action taken. Usually, they are also applied at the end of the calculations.
Google themselves hardly ever talk about penalties; they talk about manual actions, or they simply say that the algorithm has chosen to rank your site lower.
What is a filter in Google’s search results?
Filters are one of the areas that many, even those working professionally in SEO, misunderstand. Filters create problems for many because they often work very differently from the algorithm at large. It’s also getting more ambiguous.
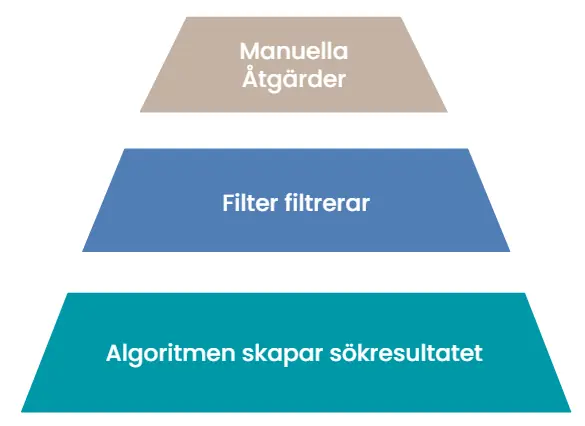
An image that often helps to think about filters is a pyramid. At the bottom, the regular algorithm creates the search results, which forms the broad base upon which all search results stand. Once that’s done, filters go through the search results and remove what shouldn’t be there. On top, at the very top, come manual actions (Manual Action) by Google’s quality team. Regardless of what the algorithm has done, filters can remove or highlight sites, and regardless of what these two instances think, Google’s employees can remove sites from the search results.
It doesn’t quite work like this, but it’s a good image. For periods of time, we’ve also been told when filters are run, so it’s been clear what happens. We will specifically talk about Panda and Penguin, which are the two most well-known filters Google has run. There are many others that have come and gone over the years, but these are big and have had a broad impact. Both are now a permanent part of the algorithm, but for a while, they were run separately, with a few weeks or months between each.
What happened when Panda was run

Panda is a filter that targets thin content. Thin content is unfortunately a somewhat vague definition, but think of sites that rank for many keywords without actually adding any value. Ehow is perhaps the most well-known example, with “How To” guides on everything from how to kiss to how to drink milk. The guides are written in a rush just to quickly create landing pages. Each page can generate a small amount of revenue per month from Adsense clicks, and to make it profitable, quite thin content is produced.
For those who don’t know, it’s Google’s filter to sort out weak content and the first self-learning filter Google launched (more reading about these two filters here). Let’s go through step by step what happens:
1. You make a search
2. The algorithm goes through the data and creates a search result for the phrase or word you searched for. If you have a page that can be indexed properly and is clearly about the topic and has sufficient authority, it will be able to appear.
3. A filter is then applied on top of the search result, in this case, Panda, which specifically looks for pages that are more or less mass-produced. These are excluded.
4. There is also a check if anyone on Google’s quality team has flagged the content, and if so, it is also excluded from the search result.
5. Personal, geographic, and other adjustments are made for you, and the search result is presented.
The reason Panda came into play (and later Penguin, which did similar things but on a link level) was because it was believed that the search results were filled with thin content. Large sites like Ehow created millions of articles, with questionable quality, just to appear in as many search results as possible. In Ehow’s case, they used very cheap content writers who were paid based on how many visitors the article received and were guided on which keywords to write articles for. This led to very quickly put-together articles, but with the right headline and title. Combined with a very strong link profile, they could easily secure first place for search terms like “How to drink milk.” There aren’t many searches for that term, but imagine a hundred million such terms.
Another variant was content that was simply data cut in different ways. Think about the idea that you have two recipes, one for Wienerbröd and one for Källarfranska. You place them in the categories “Matbröd” (Bread) and “Fikabröd” (Pastry) and start ranking well for those keywords. To gain some more traction, you also add them to “Bröd som innehåller Vetemjöl” (Bread containing Wheat Flour) and “Bakning” (Baking), and you start ranking for those as well. You quickly realize that the category “Bröd som innehåller smör” (Bread containing Butter) is also smart, and soon you add more and more categories where you just sort these two recipes. Every time you add a new category, you start ranking for yet another keyword. This works great until the Panda filter gets fed up and removes you from the search results (and then it’s not enough to just go back to the point just before, you need to rebuild your site until Google and Panda consider it to add value).
There are things filters can’t find but Google still hates
The next step is pages that have performed well both when the algorithm builds search results and when the filters are applied. Sometimes, things that Google hates slip through, and then a manual action is taken. For example, adult content in search results that shouldn’t clearly contain such material. Google dislikes it at such a level that Matt Cutts, the first Head of Webspam at Google, used to hand out homemade cookies to anyone who could find it in the search results.
An example of a manual action we’ve seen is “Ads Above The Fold.” There are systems to automatically remove pages that seem to be made solely for displaying ads, but sometimes Google fails to catch it if it’s not obvious that these are ads. An example is a top list of the ten best vacuum cleaners, where you get paid for traffic you drive to vacuum cleaner sellers or the sales you generate for them. It’s not always obvious to Google that this is an advertisement, but it’s something they want to avoid showing unless the page provides significant value in terms of reviews or similar content.
As mentioned, we’ve seen an example when this was manually removed from the search results, and Google is courteous enough to notify you about it in Search Console. You receive a message explaining what (in a somewhat vague manner) they believe you’ve violated and that they have taken action. Many people refer to this as being “penalized” by Google, but Google themselves do not call it a penalty—just a manual action. If this happens, you need to fix the issue and submit a reconsideration request, describing what you’ve fixed and hoping that the reviewer likes what you’ve done.
It’s possible, using less reputable methods—footer links being a current example—to temporarily gain positions but then fall like a stone later on. An experienced SEO knows this, and one could very well consider it a risk worth taking. Temporarily holding positions for a keyword that you wouldn’t normally be able to rank for could very well be a profitable strategy. However, it’s important to know what you’re doing, and that requires experience.
What is Penguin, Google’s second well-known filter

If you’ve read about search engine optimization in recent years, you’re probably familiar with Penguin. Just like Panda, it’s a filter applied to search results that removes sites that don’t meet the filter’s requirements. While Panda filters out sites with “thin content,” Penguin targets “thin link profiles” in a similar way.
What Penguin does is filter out sites that rank better than they should, not because they’ve created landing pages with thin content but because they have links that don’t have the necessary quality. Since links are a scarce resource in SEO, many have tried to maximize the results from the links they have. This primarily concerns anchor text distribution. Having a link with the anchor text “Cheap Cars” gives a clear advantage for the search term “cheap cars,” so it’s easy to be tempted to link too frequently with that specific anchor text. It was previously a less risky practice than it is today, although there were filters before, they weren’t as aggressive as Penguin.
What many have struggled with in the last year is that if you get filtered by Penguin, you can’t return to your previous rankings until the data in Penguin is updated. Previously, this was done with a gap of months, but in the past year, those who have fallen into the filter have had to stay out of the search results for almost an entire year, regardless of whether they’ve fixed the issues or not. So, what should you do if you get caught in the filter?
What you need to do to get out of Penguin
What Penguin is about is links, and if you’ve concluded that it’s actually Penguin that has affected your site, that’s where you should focus. Sometimes it can be difficult to know exactly what’s happened to a site, so first make sure it’s Penguin and not Panda or some other filter.
You need to clean up links
You need to clean up links in two steps. The first step is that you need to contact anyone who links to you in an overly aggressive manner and ask them to remove the links or set the nofollow attribute on them. Of course, this is a big job if the site has plenty of inbound links, but it needs to be done.
The next step is to use Google’s disavow tool to ask Google to ignore the links that couldn’t be removed. At least previously, it has been important not to rely solely on disavow, and it’s not 100% certain that this is still the case.
The links you need to find and eliminate are those with the following characteristics:
1. Links with commercial keywords in the anchor text, the more the anchor text exactly matches the search phrase, the more important it is.
2. Sitewide links, links from all pages on a site, the more pages a site links from, the more important it is.
3. Links with worse placement on the page. Links in body text are the least risky, links in the footer are the most risky, and other placements fall in between. As a rule of thumb, remove links that seem most unlikely to be clicked.
4. At this stage, it’s important to be quite tough on your link profile, even things that you think are borderline need to be removed—you must cut hard. The reason is that you can’t do it gradually, and Google is quite strict when you’re stuck in Penguin. When they update the data, you want to be sure you’ll come back rather than wait another six months or maybe even a year.
Panda and Penguin might not be that dangerous anymore
It started as a feeling, but after discussing it with many of the bigger players in the industry, I’m increasingly sure. Panda and Penguin have become softer. The latest Penguin update passed almost unnoticed, and hardly anyone trembles when they hear the word Panda anymore. They were launched with a bang, but now, when they show their respective faces in the SEO world, barely anyone gets nervous.
There are two theories about this phenomenon. The first is that the SEO community has now become better at handling both Panda and Penguin. When Panda first came out and sites like Reco.se and many others, which were based on Swedish business directories, plummeted in the results, many thought SEO was doomed. Of course, that wasn’t the case, and the SEO world adapted. Now, those of us who do SEO have gotten so good at handling Panda that disasters like Reco.se have disappeared.
The second theory is that Google has actually reduced the impact of both filters. Maybe because they realized that the results didn’t actually improve or due to the many “false positives” they got, where so many were filtered who didn’t deserve it. My personal opinion is that both are true; no serious SEO would index search results today, and Google has become a bit kinder. Content farms like Reco.se are no longer a problem for Google, so they’ve dialed back the impact of Panda. Similarly, Penguin isn’t needed as much anymore, so they’ve eased up on it.
Today, Penguin and Panda are integrated into the algorithm and run in a more predictable manner. Additionally, they’ve reassessed so that bad links, for example, no longer count negatively in Penguin but are simply ignored. Google themselves claim that they are quite good at this.
Pop-Up Filters
Google has long been opposed to excessive advertising on pages. Pages where a significant portion of the content is hidden behind a pop-up (not all pop-ups, for example, age verification pop-ups required by law are excluded from this filter) will get lower rankings in an effort to improve the search engine experience for mobile users. It can be assumed that this filter does not apply to cookie pop-ups.
Some examples of pop-ups that Google identifies as interfering with the user experience for mobile users include ads that hide other content, pop-ups that must be closed before accessing content, and those that push the actual content out of view.
Google has stated that for several years now, they have simply downgraded the rankings of such pages, though we are more skeptical about whether this is truly the case.
The problem with learning a tactic instead of understanding
Too often, SEO professionals, both amateurs and experts, get stuck in a tactic. They have learned a tactic for doing SEO rather than truly understanding the search engine. We see this all the time, especially when it comes to adding pages to a site to rank. Large Swedish e-commerce sites often force new categories regularly because it gives good results in the short term. The SEO specialist they use has learned that if they add a category like “Bread that contains butter” and set the right title and header, the site will start ranking for searches related to butter and bread. The problem is that if you keep using this tactic, over time, you end up in a situation where Google completely loses trust in the site, and it disappears from ALL search results.
If you have 6 or 12 months of SEO experience, you’ve simply never encountered a filter. You might have purchased a keyword domain, installed WordPress with Yoast, and built links to it until it ranks, and suddenly, you think you’re an SEO expert. There’s nothing wrong with WordPress, Yoast, or links, but it’s a matter of time horizon.
I once achieved first place in the U.S. for highly competitive keywords with a site that had five hastily written pages and footer links from 2.4 million Russian sites (at a total cost of $500). It’s a tactic that works, and it worked great for the five days the site was in Google’s index.
What is a manual action?

Google’s manual actions have two main functions. The first is to “urgently” remove a site or page from search results where they do not want to show it, but where the algorithm and filters are not enough to assess it. This can be done in different ways. For example, it might mean that Google stops crawling the site and removes it from the index that the algorithm uses to select sites. So, it will not even be considered in search results. It can also mean that one or more links are given a negative value, making the site rank lower when the PageRank algorithm is applied, and thus making it harder to achieve a good position when the list is later refined. In some cases, manual actions work in the same way as filters, applied at the end of the calculations; for example, you might be moved down 10 positions or always have to appear at the very end of a list of 1,000 results.
The second function of manual actions is to collect data to help build new or improve existing algorithms and filters. All (or at least most) manual actions are communicated through Google Search Console. You’ll get a notification saying that a manual action has been taken against your site, along with a brief explanation of why. This could be anything from bad links and poor content to too many ads on pages. Once you receive this notification, you should work on improving the issues they’ve pointed out. When you believe you have fixed them, you can send a message to Google explaining what you have done, apologizing, and assuring them it won’t happen again. If they are satisfied with your changes, the action will be lifted.
What is the difference between a manual action and a filter?
Actually, not much. The main difference is that they exist in areas where Google believes it has enough data to let a computer make the decisions instead of a human, and as mentioned, they are always applied once the search results have already been built. What differs is how you stop being filtered. Filters are essentially a rule for a specific thing, a threshold that you need to stay above or below.
Very simplified, it’s about staying on the right side of each such value. As long as you do that, everything is fine. If you go beyond a threshold, you get filtered, and when you return to the right side (and over a threshold), the site is allowed again. It’s not really that simple, though. The thresholds are not always static. They can change over time, and Google doesn’t openly disclose what filters they have or where the boundaries lie. At least not directly. Another aspect that makes it harder is that some filters are always run based on the index Google has, while others are updated more or less regularly.
Who can be “penalized” by Google?
Sometimes, you get stuck in a filter or manual action because you’ve consciously taken a calculated risk. Sometimes, it’s because of aggressive SEO. More often than not, people end up in filters or receive a manual action simply because they didn’t realize it was something that could happen. A clear example of this is the many times Google has penalized itself. For instance, in 2012, when Google Chrome (which was new at the time) was prevented from ranking in search results.
A manual action example with a slight aftertaste
Is it possible for a site to return to search results just days after Google has applied a manual action against it? Thumbtack managed to recover in 6 days after the site couldn’t even be found under its own name. Could this have something to do with the owners?
In 2015, Thumbtack received a manual action and for a brief period, it couldn’t even be found for its own name in the search results. Recovering from a manual action is usually a long and drawn-out process, often requiring a lot of work and multiple “reconsideration requests” sent to Google, which typically takes months to respond. More often than not, you have to repeat the process several times. Of course, there were many rumors in the SEO world when this happened, especially since Google was the main shareholder of the company.
First, you need to have the action lifted, which in itself can take weeks. You must first address the issue, in this specific case, remove as many bad links as possible and upload a disavow. Then you need to formulate this in a reconsideration request, and if you’ve sufficiently begged for forgiveness, Google’s quality reviewers will lift their penalty. At that point, you’ll have removed a significant portion of your links and won’t be able to maintain the rankings you once had. You simply won’t be able to fully recover from a link-based penalty. If it’s a more common type of penalty, such as issues on the site itself, it’s a different story. For example, if you have too many “ads above the fold,” it’s not difficult to fix quickly.
For Thumbtack, the situation seems different. Just 6 days after they were removed from the results, they’re now back stronger than ever.
It’s commendable that Google actually chose to apply a manual action against a site they themselves own, but this story reveals several secrets. The first is that if there hadn’t been blog posts about their link building, they probably wouldn’t have acted against it, at least not right now. The second is that if you’ve received an investment from Google, while you’ll be treated just like everyone else temporarily, it doesn’t seem too hard to get back in Google’s good graces again. The third and perhaps most cynical conclusion is that Google likely wants to reward its own sites in the search results. The question is just how much they can do this before the courts step in.
