


There are essentially two ways to ensure that a page is not displayed in, or accessible from, search engine results. Depending on when and how they are implemented, they have slightly different effects. Here, we explain when and why you should use the different methods.
Noindex tags
The most common, simplest, and most effective method—one that works in all situations—is to apply a “noindex” tag. This can be implemented either as a meta tag or sent via the HTTP header, in which case it is called an X-Robots tag. Both work in the same way. This is what the meta tag looks like in the code:
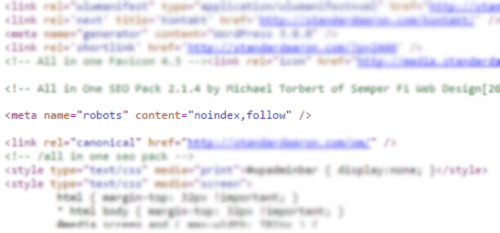
What a noindex tag does is tell the search engine crawler that it is allowed to read the page, but that it should not be stored in the index and therefore not be searchable. In the vast majority of cases, the crawler does exactly that (you can never fully trust crawlers; they sometimes miss things). This means that if the page already exists in the index, it will be removed, and if it does not, it will not be added.
Robots.txt
The other method is to block pages using a robots.txt file. This is a file that tells search engines whether they are allowed to read a page or not. However, it does not tell the crawler whether it is allowed to store the URL and the page in its index. This is the crucial point, and almost always the reason why a blocked page remains in the index.
If Google has not indexed the page previously, it will generally just ignore it. Since it is not allowed to visit the page, it leaves it alone. The problem arises when the page is already in the index. Google will then want to visit it from time to time to see if it has changed. If that page is blocked in robots.txt, Google is not allowed to visit it, so it will “remove the content” from its index but keep the URL itself. Google wants to see if the page returns. Google’s dream is to have all text ever created in its index, but since it cannot know whether the same content is still there, it indicates in its search results that the page is blocked.
The solution
Robots.txt is not a bad tool in itself, but it is quite blunt. The solution is either to always add URLs to the file before they are published, or—preferably—to use “noindex” only, to be on the safe side.
